
链表 #
**链表(linked list)**是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“引用”相连接.引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点.
这样就可以让各个节点分别存储在不同地址,内存无需连续
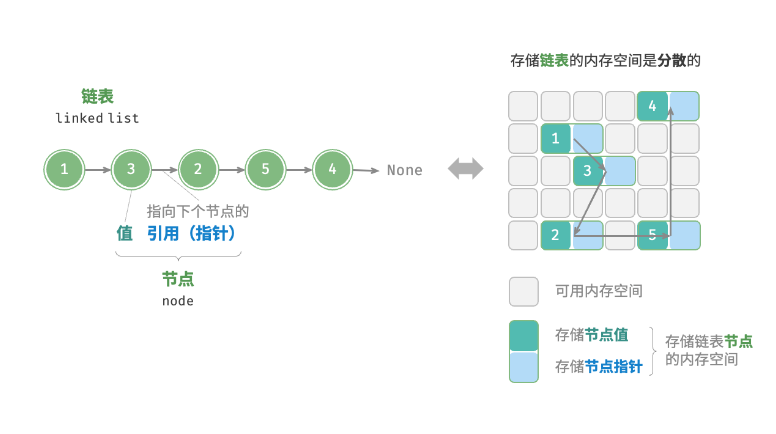
- data:数据,就是节点的值
- next指针:指向下一个节点的指针
这也就是说链表比数组占用更多的内存空间
/* 链表节点结构体 */
typedef struct ListNode {
int val; // 节点值
struct ListNode *next; // 指向下一节点的指针
} ListNode;
/* 构造函数 */
ListNode *newListNode(int val) {
ListNode *node;
node = (ListNode *) malloc(sizeof(ListNode));
node->val = val;
node->next = NULL;
return node;
}头节点 #
单链表开始节点前可以设立一个节点成为头节点,它的数据域可以不存储任何信息也可以存储链表长度等信息,头结点的指针域指向第一个节点(首元节点)的指针
头指针 #
链表中指向第一个节点的指针,有头节点时指向头结点,无头节点指向首元节点
单链表(带头节点) #
链表初始化 #
建立链表分为两步,第一步是初始化各个节点对象,第二步是构建节点之间的引用关系.初始化完成后,我们就可以从链表的头节点出发,通过引用指向next依次访问所有节点.
/* 先定义一个带头节点的单链表 */
typedef struct LNode{ //定义单链表节点类型
ElemType data; //每个节点存放一个数据元素
struct LNode *next; //指针指向下一个节点
}LNode, *LinkList; //LNode 是节点类型,LinkList是指向LNode这种节点的指针类型
// 初始化一个单链表(带头结点)
bool InitList(LinkList &L){
L = (LNode * ) malloc(sizeof(LNode)); //分配一个头节点
if(L == NULL) // 内存不足,分配失败
return false;
L->next = NULL; //头节点之后暂时还没有节点
return true;
}链表插入节点(按位序插入) #
链表插入节点非常容易,只需要改变插入节点前节点的指针即可,时间复杂度为O(1)
相比数组插入元素的时间复杂度O(n),效率高多了
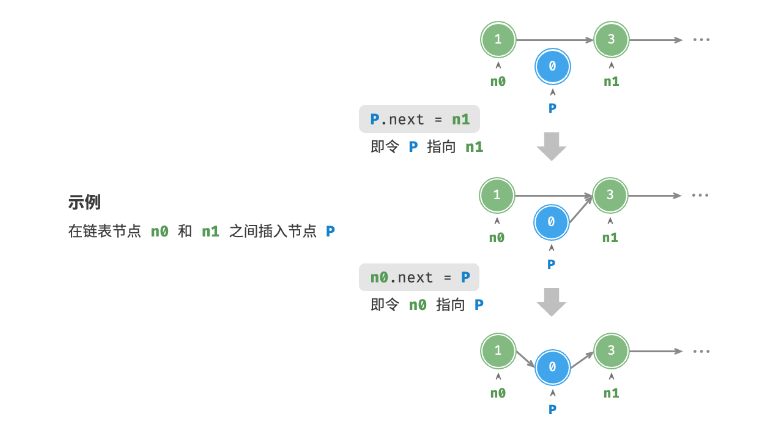
//在第 i 个位置插入元素e(带头结点)
bool ListInsert(LinkList &L, int i, ElemType e){
if(i < 1)
return false;
LNode *p; //指针p指向当前扫描到的节点
int j = 0; //当前p指向的是第几个节点
p = L; //L指向头节点,头节点是第0个节点(不存数据)
//寻找第 i-1 个节点
while(p != NULL && j < i-1){ //循环找到第 i-1 个节点
p = p->next;
j++;
}
if(p == NULL) //i值不合法
return false;
//新建一个节点并赋值要插入的数据e
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = e;
//开始插入
s->next = p->next; //先将新节点的next指向第 i 个节点
p->next = s; //将节点s连接到p之后
return true; //插入成功
}链表删除节点 #
与插入一样,删除也只需要改变一个节点的指针
// 按位序删除,i=1删表头,i=length删头尾
bool List_Del (LinkList &L, int i, ElemType &e) { //删除时返回删除的元素
if (i < 1 || i > List_Length(pHead)) return false; //删除位置不合法
LNode *p; //指针p指向当前扫描到的节点
int j = 0; //当前p指向的第几个节点
p = L; //L和p相同,都指向头节点
//寻找第 i-1 个节点
while(p != NULL && j < i-1){ //循环找到第 i-1 个节点
p = p->next;
j++;
}
LNode *q = p->next; // q指向待删除结点
e = q->data; //返回即将删除的数据
p->next = q->next; // 将q节点从链中“断开”
free(q); //释放节点的存储空间
return true; //删除成功
}访问节点 #
链表的访问效率很低,因为访问需要从头节点一个一个的寻找next节点,时间复杂度为O(n)
/* 访问链表中索引为 index 的节点 */
ListNode *access(ListNode *head, int index) {
for (int i = 0; i < index; i++) {
if (head == NULL)
return NULL;
head = head->next;
}
return head;
}查找节点 #
/* 在链表中查找值为 target 的首个节点 */
int find(ListNode *head, int target) {
int index = 0;
while (head) {
if (head->val == target)
return index;
head = head->next;
index++;
}
return -1;
}建立单链表 #
建立单链表常用的方法有头插法和尾插法
尾插法 #
新节点总是插入在链表的尾部(最后一个位置)。
尾插法的特点是每插入一个新节点,链表的尾节点指针(pTail)会更新为新插入的节点,使其始终指向当前链表的尾结点。从而使得输入的数据在链表中按顺序存储>。 当输入数据为 999 时,循环结束,将尾节点的 next 指针置为 NULL 表示链表结束,函数返回最终的链表头节点。
// 创建链表-通过尾插法
LinkList List_Create_Tail_Insert(LinkList &pHead) {
LNode *pTemp; // 临时节点指针
LNode *pTail = pHead; // 尾节点指针,初始指向头结点
int x; // 用于存储输入的数据
scanf("%d", &x);
while (x != 999) {
pTemp = (LNode *)malloc(sizeof(LNode)); // 分配内存并创建新节点
pTemp->data = x; // 尾节点的下一个指针指向新节点
pTail->next = pTemp; // 更新尾节点指针,使其指向新节点
pTail = pTemp; // 读取下一个数据
scanf("%d", &x);
}
pTail->next = NULL; // 尾节点的下一个指针置为 NULL,表示链表结束
return pHead; // 返回带头结点的链表头指针
}头插法 #
头插法的结果为倒序
该代码通过头插法创建一个链表. 头插法的特点是每插入一个新节点,链表的头节点就会变成新插入的节点,从而使得输入的数据在链表中是倒序存储>的. 当输入数据为 999 时,创建链表的循环结束,函数返回最终的链表头节点.
// 创建链表,头插法结果为倒叙
LinkList List_Create(LinkList &pHead) {
LNode *pTemp; int x; // 临时节点指针
scanf("%d", &x);
while (x != 999) {
pTemp = (LNode *)malloc(sizeof(LNode)); // 分配内存并创建新节点
pTemp->data = x;
pTemp->next = pHead->next; // 新节点的指针指向当前头节点的下一个节点
pHead->next = pTemp; // 头指针指向新节点,使其成为新的头节点
scanf("%d", &x);
}
return pHead; // 返回带头结点的链表头指针
}双链表 #
单链表结点中只有一个指向其后继的指针,使得单链表只能从前往后依次遍历.要访问某个结点的前驱(插入、删除操作时),只能从头开始遍历,访问前驱的时间复杂度为 O(n). 为了克服单链表的这个缺点,引入了双链表,双链表结点中有两个指针prior和next,分别指向其直接前驱和直接后继.
双链表的主要特性 #
- 双向遍历由于每个节点都有前后两个指针,因此可以在列表中双向遍历,无需像单链表那样只能从头节点开始向前遍历。
- 插入与删除的便捷性:在双链表中插入或删除一个节点时,只需改变相应节点的前后节点的指针指向即可,操作相对简单高效。
数据结构 #
- data:数据域,也是节点的值
- prior:指针域,指向前一个结点的指针
- next:指针域,指向下一个结点的指针
/* 双链表中查找值为 target 的首个节点 */
typedef struct DNode {
int data; // 数据
struct DNode *prior, *next; // 前驱和后继指针
} DNode, *DLinkList;双链表在单链表结点中增加了一个指向其前驱的指针 prior ,因此双链表的按值查找和按位查找的操作与单链表的相同.但双链表在插入和删除操作的实现上,与单链表有着较大的不同. 这是因为“链”变化时也需要对指针 prior 做出修改,其关键是保证在修改的过程中不断链. 此外,双链表可以很方便地找到当前结点的前驱,因此,插入、除操作的时间复杂度仅为 O(1).
按位序插入节点 #
// 按位序插入,i=1插在表头,i=length+1插在表尾
bool DList_Insert(DLinkList &pHead, int i, int e) {
if (i < 1 || i > DList_Length(pHead) + 1)
return false;
int j = 0; // 当前p指向的是第几个结点
DNode *p = pHead; // p 指向头结点
while (p != NULL && j < i - 1) { // 循环找到要插入位置的前驱结点
p = p->next;
j++;
}
DNode *pTemp = (DNode *)malloc(sizeof(DNode));
pTemp->data = e;
pTemp->next = p->next;
pTemp->prior = p;
// 又后续结点,不是空链表
if (p->next != NULL) {
p->next->prior = pTemp;
}
p->next = pTemp;
return true;
}按位序删除节点 #
// 按位序删除,i=1删表头,i=length删头尾
bool DList_Del (DLinkList &pHead, int i) {
if (i < 1 || i > DList_Length(pHead))
return false;
DNode *p = pHead;
// 找到待删除位序的前一位结点
for (int j = 0; j < i - 1; j++)
p = p->next;
DNode *q = p->next; // 待删除结点
p->next = q->next;
if (q->next != NULL)
q->next->prior = p;
free(q);
return true;
}```